如何利用id类特征
为什么用
会极大提高模型的个性化能力和实际效果。而且可以对抗热度穿透现象。
直接加入id类特征,尽管并不能实现完全的个性化,但是可以把每个用户的行为模式区分开,从而提高了其他特征的泛化能力。
例如有两个id和一项特征来进行一个回归预测。一个id是正常用户,一个id是刷子用户。式子可以表示为w1x1+w2x2+w3x3=rate
对于正常用户rate值低,刷子用户rate值高。即w1x1+w3x3值较小,w2x2+w3x3值较大。可得是w2x2项较大即模型学习到了提高w2,对于不同的id就进行了区别对待。
加入id类特征的价值:
- 可以使得在学习过程中每个人的信号更合理地影响整体模型,使得模型泛化能力更好。
- 可以使得模型能够对每个id有更细粒度的排序能力,使得模型的个性化效果更好。
怎么用
- id类特征上的信号是及其稀疏的,所以意味着我们需要更大量的数据,但是其实这并不困难,在计算广告,推荐系统的场景下,单个id上收集的数据其实是非常多的,但是一定要通过正则化的方法来限制以使id类特征不过拟合。
- id类特征在预测中的命中率可能并不高,但这其实也不是问题。因为一个特征就是一个体系,一个体系化的特征是通过层次化的特征设计来达到命中率和个性化的综合。比如说 用户id->用户GPS坐标+用户喜好Tag+用户最近行为->用户年龄,用户性别。通过分层,由最细粒度到最粗粒度的特征搭配来保证特征命中率。
- 组合。单独的id类特征时意义并没有那么高,有意义的是不同层次的交叉组合。userid和itemid交互后,也就是用户对物品的评分矩阵,这时候就可以使用itemcf或svd等等。
- 模型和算法。实际上,LR是适合使用ID类特征One-hot编码的,原因在于LR适合接受超高维度的特征输入。但是这么做的前提是训练样本足够多。对于XGBoost,DNN,就要先对id特征one-hot进行embedding。
Entity Embeddings of Categorical Variables
https://arxiv.org/pdf/1604.06737.pdf
Intorduction
神经网路不适合去拟合非连续的函数,因为其假定一般形式具有连续性。在训练阶段,数据的连续性保证了优化的收敛性,在预测阶段,输入值的微小变化保证了输出的稳定。另一方面,决策树不假定特征变量有任何的连续性。
有意思的是,如果我们使用了正确的表示数据的形式,在现实世界中,我们面对的问题总是连续的。每当我们找到了一个更好的方式来表示连续数据,就提升了神经网络学习数据的能力。比如NLP是由于使用了w2v去将one-hot转为了连续的向量。
不同于自然中存在的非结构化数据,机器学习中使用的结构化数据可能很难发现连续性质。神经网络连续函数的特性限制了对于类别变量的应用。embedding解决了one-hot的两个问题,一是太过稀疏,而是类与类之间没有关联。
记号:(h,r,t),h和t是两个实体,r是关系。
在w2v中发现隐向量具有如下的关系: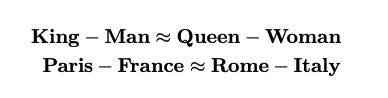
w2v除了使用常规的滑动窗口学习还可以使用标记进行监督学习。
以及说树是结构化数据中用的最多的模型。以及该方法针对的是表格数据中的离散目标值,也就是类别值。
Entity Embedding
embedding层的维度D是个超参数。范围是[1,m-1],m是类别数。在实际中,根据实验来确定最后的维度数。下面是一些经验之谈,一,大体的估计一下需要描述的维度,二如果不知道怎么下手,从m-1开始。
定义衡量两个隐向量相似度的方法。最简单的就是隐向量求距离。
a example for dimension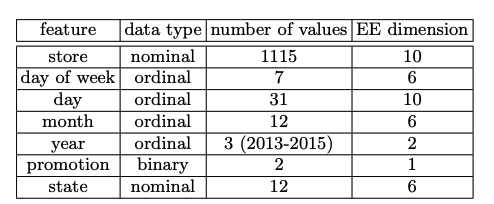
原始的数据是两部分,第一部分是train.csv,包含了2.5年的每日销售数据,包括1115种不同的商店,共计有1017210条数据。第二部分是关于1115店的更详细的信息。除了主办方给出的数据,外部的数据同样重要,比如日期的天气信息,流行信息,甚至于重大比赛的日期信息。
业务实践
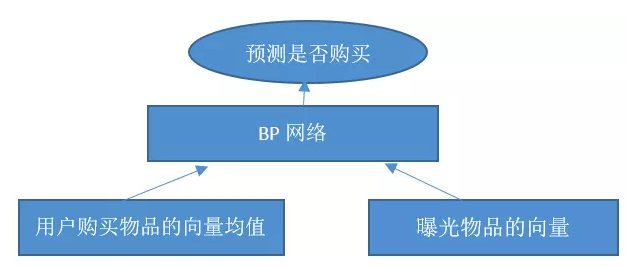
场景:网络购物场景中,运用W2V+BP进行个性化推荐。
- 对物品进行向量化,把每个用户看作一篇文章,用户购买物品按照时间序列排序,物品看作词,带入W2V模型得到物品的向量。
- 样本收集,收集客户端中,对用户的物品曝光及购买记录,以用户历史购买的物品列表作为用户画像,以给用户曝光物品后用户是否购买为目标变量。
- 构造W2V + BP的模型,模型的输入有两个,第一个为用户历史购买物品的向量均值,第二个为曝光物品的向量。模型的输出为用户是否购买曝光的物品,中间用BP网络进行连接。
- 模型训练与使用,模型训练:目前业界一般使用TF进行实现,BP网络的节点数及层数需要根据训练情况确定。模型使用:给定一个用户u及一个物品i,把用户u购买物品向量均值及物品i的向量作为模型输入,计算物品i的模型得分。重复该操作,计算出用户u所有候选物品的模型得分,根据物品的模型得分降序推荐给用户。